
AI security best practices have become critical as generative AI and agentic systems operate at scale, expanding the attack surface faster. New risk areas are emerging around memory integrity, cross-agent exploitation, and model behavioral drift. Traditional security frameworks don’t deal very well with these challenges. The OWASP GenAI Security Project, a global open-source initiative, provides useful guidance to identify and mitigate these risks.
This piece explores generative ai security best practices drawn from OWASP’s frameworks. We cover enterprise ai security best practices to govern systems, ai data security best practices to protect sensitive information, and agentic ai security best practices to manage autonomous systems. You’ll find practical gen ai security best practices tools and implementation strategies to secure your AI applications in production.
Understanding the OWASP GenAI Security Project
“As AI adoption accelerates faster than ever, security best practices must keep pace. The community’s responsiveness has been remarkable, and this Top 10, along with our broader open-source resources, ensures organizations are better equipped to adopt this technology safely and securely.” — Scott Clinton, Co-Chair, Board Member, and Co-Founder of OWASP GenAI Security Project
The OWASP GenAI Security Project operates as a global community-driven and expert-led initiative that creates freely available open-source guidance to understand and mitigate security concerns in generative AI applications. This umbrella project brings together various specialized initiatives. Each addresses specific aspects of AI security through focused working groups.
What the Project Covers
The project spans a wide range of security topics for GenAI and LLM-based applications. It covers multiple initiatives including Secure AI Adoption, which establishes Centers of Excellence for security frameworks and governance policies. AI Red Teaming guidelines provide standardized methodologies for adversarial testing. The Agentic Security Research Initiative explores security implications of autonomous systems using frameworks like LangGraph and AutoGPT.
The project released the OWASP Top 10 for Agentic Applications after more than a year of research and refinement. This reflects input from over 100 security researchers, industry practitioners, and leading cybersecurity providers. The framework went through evaluation by an Expert Review Board including representatives from NIST, European Commission, and the Alan Turing Institute.
Key Frameworks and Resources
The life-blood of OWASP’s approach centers on the LLMDevSecOps lifecycle, which embeds security into nine distinct stages from scope and planning through governance. This lifecycle adapts familiar DevOps principles for the unique challenges of Large Language Models.
The project categorizes specialized security solutions into practical tool types:
- LLM Firewall: Monitors and filters prompts and responses to block malicious inputs and prevent data exfiltration
- LLM Automated Benchmarking: Assesses security weaknesses through vulnerability scanning
- LLM Guardrails: Enforces ethical and legal boundaries on model behavior
- AI Security Posture Management (AI-SPM): Provides integrated security visibility across the AI lifecycle
- Agentic AI App Security: Focuses on securing autonomous agent applications
The Solutions Landscape Matrix maps dozens of open-source and proprietary gen ai security best practices tools to lifecycle stages and the OWASP Top 10. Organizations can identify security coverage gaps.
Why These Best Practices Matter
These enterprise ai security best practices address critical business risks that extend beyond technical vulnerabilities. Organizations face regulatory compliance gaps that could result in substantial fines under emerging AI regulations. They also face intellectual property theft through model extraction attacks and operational disruption from adversarial attacks. Reputational damage from biased or manipulated outputs poses another risk. Traditional application security playbooks prove insufficient against threats like prompt injection and model poisoning. These agentic ai security best practices become essential for protecting AI deployments.
Core Security Frameworks from OWASP GenAI

Image Source: OWASP Foundation
Four interconnected frameworks are the foundations of OWASP’s ai security best practices. Each addresses distinct vulnerability categories in the AI application lifecycle.
OWASP Top 10 for LLM Applications
This framework identifies critical security vulnerabilities in systems built on large language models. The 2025 version covers: Prompt Injection (manipulating LLMs through crafted inputs), Sensitive Information Disclosure (failure to protect confidential data in outputs), Supply Chain vulnerabilities (compromised components undermining system integrity), Data and Model Poisoning (tampered training data impairing model accuracy), Improper Output Handling (insufficient validation leading to downstream exploits), Excessive Agency (unchecked autonomy causing collateral damage), System Prompt Leakage (exposing system instructions), Vector and Embedding Weaknesses (security risks in embedding systems), Misinformation (inaccurate outputs compromising reliability), and Unbounded Consumption (resource exhaustion through uncontrolled processing).
Each vulnerability presents ground attack scenarios. To name just one example, insecure output handling can enable cross-site scripting or remote code execution when organizations fail to treat LLM outputs with zero trust validation.
OWASP Top 10 for Agentic AI Systems
This framework reflects input from over 100 security researchers addressing autonomous agent risks after more than a year of research. Agent Behavior Hijacking, Tool Misuse and Exploitation, and Identity and Privilege Abuse showcase how attackers subvert agent capabilities. These agentic ai security best practices prove essential as companies face exposure to attacks and often don’t realize agents operate in their environments.
Threat Defense COMPASS Framework
COMPASS combines AI threats, vulnerabilities, defenses and mitigations into a unified dashboard for rapid threat prioritization. Given as a Google Sheet template with an accompanying runbook, it makes it possible for organizations to assess external adversaries using AI tools and internal deployments of enterprise systems. The framework uses a 5-point scoring system based on impact and likelihood scales.
MCP Server Security Guidelines
MCP security guidelines establish baseline controls for Model Context Protocol server deployment. All remote servers must use OAuth 2.1 with short-lived, scoped tokens that are validated on every call. Session isolation requirements prevent user data leakage across contexts. Tool security demands cryptographic signatures for every tool definition.
Generative AI Security Best Practices for Implementation
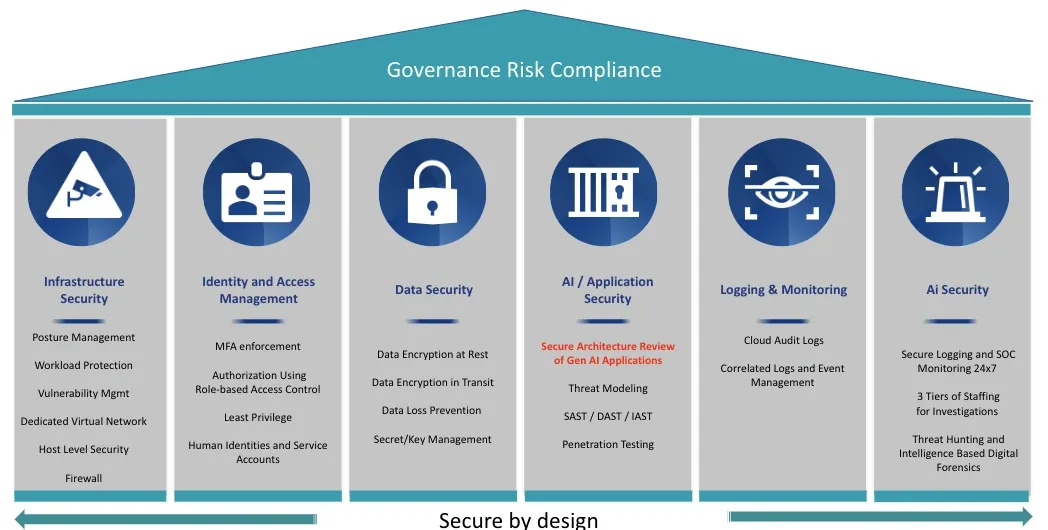
Image Source: Cloud Security Alliance (CSA)
AI security best practices need controls for authentication, input validation, data protection, behavioral monitoring and memory safeguards.
Authentication and Authorization Controls
AI systems need authentication through API keys stored as named values, managed identities with role assignments or OAuth 2.0 tokens for fine-grained access. Authorization operates at four control points. Question Control filters prompts at the source. Data Access Control makes sure RAG systems retrieve only user-authorized documents. Service and Tool Access governs MCP protocol permissions, and Response Masking redacts sensitive information based on identity and policies. Agents should inherit permissions from the specific user they represent. Use short-lived tokens that expire quickly and can be revoked instantly.
Prompt Injection Prevention
Verify and sanitize all user inputs before they reach the LLM. Use pattern matching to detect dangerous instruction sequences. Structured prompts with clear separation between system instructions and user data prevent manipulation. Research shows 89% success rates on GPT-4o and 78% on Claude 3.5 Sonnet with sufficient attempts. Content classifiers that filter harmful data containing malicious instructions across emails and files should be deployed. Human-in-the-loop controls require user confirmation for high-risk operations with passwords, API keys or system overrides.
Data Security Best Practices for AI Systems
AI data needs end-to-end encryption at rest and in transit. Log and monitor data access, and implement complete backup strategies. Data minimization reduces breach exposure by collecting only necessary information for specific AI applications. Authorization decisions must occur before data reaches the LLM, as models cannot make access control decisions during inference. Secure side channels communicate end-user identity to backend APIs and enable deterministic authorization mechanisms that filter data based on proven user permissions.
Model Behavioral Drift Monitoring
Drift refers to gradual performance degradation caused by changes in data distributions or user behavior. Data drift measures statistical changes in input prompt embeddings, whereas concept drift tracks evolving relationships between inputs and desired outputs. Baselines from stable production periods should be established. Monitor embeddings with Wasserstein distance rather than Kolmogorov-Smirnov tests for multi-dimensional spaces, and trigger alerts when thresholds are breached. LLM-as-a-judge approaches classify drift nature by comparing drifted prompts to reference baselines. Changes are categorized as new topics, intent shifts or complexity increases.
Memory Integrity Protection
Memory poisoning embeds malicious instructions into persistent knowledge bases and influences every future agent decision. Unlike prompt injection that affects single responses, poisoned memory activates when agents retrieve it as context. Success rates exceed 80%. Defense requires memory partitioning across privilege levels, input sanitization that blocks direct writes to long-term storage and provenance tracking with source identification, timestamps and cryptographic checksums. Temporal decay functions should be applied so stored instructions reduce to less than 10% influence after 48 hours in sensitive environments.
Enterprise AI Security Best Practices and Governance
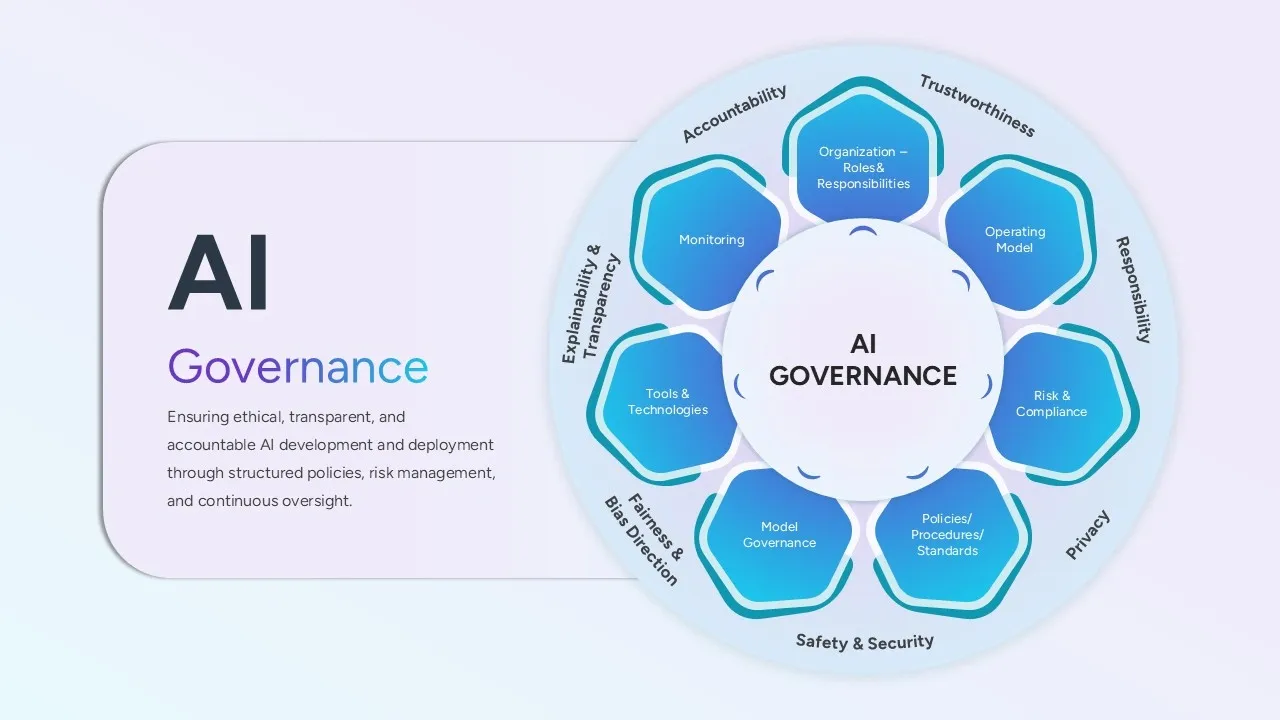
Image Source: SlideBazaar
“Explicitly defining behavioral risks like tool misuse and goal hijacking provides the C-suite and agent builders the framework needed to move from cautious experimentation to confident, scalable deployment.” — Josh Devon, Co-founder and CEO, Sondera
Enterprise governance changes AI security best practices from technical controls into business accountability structures. Nearly 95% of AI pilots never reach production, so governance frameworks set up who owns deployment decisions before systems operate in sensitive environments.
Building an AI Risk Ownership Framework
The NIST AI Risk Management Framework requires organizations to define explicit ownership for AI system risks. Ownership models include centralized (Chief AI Officer led), federated (business-led with central oversight), or hybrid RACI structures. A senior executive with board visibility should be assigned ultimate ownership. Operational tasks distribute across business, ML and compliance teams. Defense deployments demonstrate that responsibility for AI outcomes must be assigned before production introduction.
Red Teaming and Adversarial Testing
Red teaming identifies vulnerabilities through adversarial simulation, adversarial testing of specific components and capabilities testing for dangerous behaviors. Organizations should institutionalize AI red teaming as part of risk frameworks with regular testing under adversarial conditions. Automated red teaming uses AI-powered tools to probe systems for prompt injection attempts, jailbreak prompts and toxicity generation.
Incident Response for AI Systems
AI incidents just need specialized response beyond traditional cybersecurity measures. The AI Incident Response Framework adapts the NIST lifecycle (Preparation, Detection and Analysis, Containment, Eradication, Recovery, Post-Incident Activities) for AI-specific failure modes. Organizations need predefined playbooks that specify how to identify incidents, who owns response, how to contain harm and how to document root causes. Traditional SOCs must evolve into AI-SOCs with telemetry capturing prompt logs, model inference activity, tool executions and memory state changes.
Operationalizing Security in Production
Production AI demands MLSecOps practices that extend traditional DevSecOps into machine learning operations. Organizations maintain an AI Bill of Materials (AIBOM) that inventories datasets, model components and external dependencies. Advanced deployments introduce an AI Control Plane where every action passes through policy enforcement points that verify request permissions before execution. Defense architectures implement two-phase execution: models propose actions, then control layers assess proposals through policy checks and human approval when required.
AI Supply Chain Transparency
AI supply chain attacks target training data, model weights and dependencies through data poisoning and malicious model injection. Organizations should implement cryptographic verification of model artifacts to ensure deployed models match tested versions. Trusted repositories just need cryptographic signing of uploaded model files. Downstream users must treat pretrained models as untrusted by default and validate before integration. Supply chain security extends to custom third-party risk assessments that check for ISO/IEC 27001 certifications and validation mechanisms.
Conclusion
I’ve explored how OWASP’s complete frameworks address vulnerabilities in generative and agentic AI systems. We covered practical implementation strategies spanning authentication controls, prompt injection prevention and data protection. These enterprise ai security best practices provide organizations with applicable guidance to secure AI deployments against emerging threats. Governance structures and red teaming practices ensure accountability extends beyond technical teams into executive leadership and enables confident production scaling.
Key Takeaways
The OWASP GenAI Security Project provides essential frameworks for protecting AI applications against emerging threats that traditional security measures can’t address.
• Implement multi-layered authentication controls with API keys, OAuth 2.0 tokens, and role-based permissions to secure AI system access points.
• Deploy prompt injection defenses using input validation, structured prompts, and human-in-the-loop controls for high-risk operations.
• Monitor behavioral drift continuously through embedding analysis and baseline comparisons to detect model performance degradation early.
• Establish executive AI risk ownership with clear RACI structures and board-level accountability before production deployment.
• Protect memory integrity through partitioning, input sanitization, and provenance tracking to prevent persistent poisoning attacks.
The OWASP frameworks transform AI security from reactive patching into proactive risk management, enabling organizations to scale AI deployments confidently while maintaining robust security postures across the entire application lifecycle.
FAQs
Q1. What is the OWASP GenAI Security Project and why is it important? The OWASP GenAI Security Project is a global, community-driven open-source initiative that provides guidance for identifying and mitigating security risks in generative AI applications. It’s important because traditional security frameworks don’t adequately address new AI-specific threats like prompt injection, model poisoning, and memory integrity attacks that can compromise AI systems at scale.
Q2. What are the most critical vulnerabilities in LLM applications according to OWASP? The OWASP Top 10 for LLM Applications identifies critical vulnerabilities including prompt injection (manipulating models through crafted inputs), sensitive information disclosure, supply chain compromises, data and model poisoning, improper output handling, excessive agency, system prompt leakage, vector and embedding weaknesses, misinformation generation, and unbounded resource consumption.
Q3. How can organizations prevent prompt injection attacks in AI systems? Organizations can prevent prompt injection by validating and sanitizing all user inputs before they reach the LLM, using structured prompts that clearly separate system instructions from user data, deploying content classifiers to filter malicious instructions, and implementing human-in-the-loop controls that require user confirmation for high-risk operations involving sensitive data or system changes.
Q4. What is memory poisoning in AI systems and how can it be prevented? Memory poisoning involves embedding malicious instructions into an AI system’s persistent knowledge base, which then influences every future decision when the agent retrieves that information. It can be prevented through memory partitioning across privilege levels, input sanitization that blocks direct writes to long-term storage, provenance tracking with cryptographic checksums, and applying temporal decay functions to reduce the influence of stored instructions over time.
Q5. What governance structures are needed for enterprise AI security? Enterprise AI security requires explicit risk ownership frameworks with senior executive accountability, clear RACI structures defining roles and responsibilities, regular red teaming and adversarial testing, specialized AI incident response playbooks, MLSecOps practices for production monitoring, and AI supply chain transparency including cryptographic verification of model artifacts and maintaining an AI Bill of Materials.