
Teams that can’t explain their data’s origin, changes, or results face AI systems that simply don’t work. This vulnerability destroys trust and makes AI applications less effective in industries of all types.
AI data governance tackles this challenge head-on by creating a well-laid-out framework that manages information throughout its lifecycle. Data lineage reveals data’s journey and transformations across systems. It provides detailed audit trails that track every change. Data provenance shows where data originated and its complete history. These elements are the foundations of responsible AI governance. AI systems become ‘black boxes’ without reliable provenance mechanisms. Users, regulators, and affected communities can’t see how training and analyzed data transform.
This piece dives into how data lineage and provenance complement each other to maintain data quality and integrity. A clear data provenance framework helps organizations cut redundancy, control quality better, and create trustworthy AI systems. Data lineage becomes your AI pipeline’s backbone, and reproducibility transforms from a challenge into a natural habit.
Defining Data Lineage, Provenance, and Their Role in AI Governance
The way data flows through AI systems are the foundations of good governance. Data lineage and provenance each play unique but complementary roles that help build trustworthy AI systems. Let’s get into what these concepts mean and how they work within AI governance frameworks.
What is Data Lineage? (Definition and Meaning)
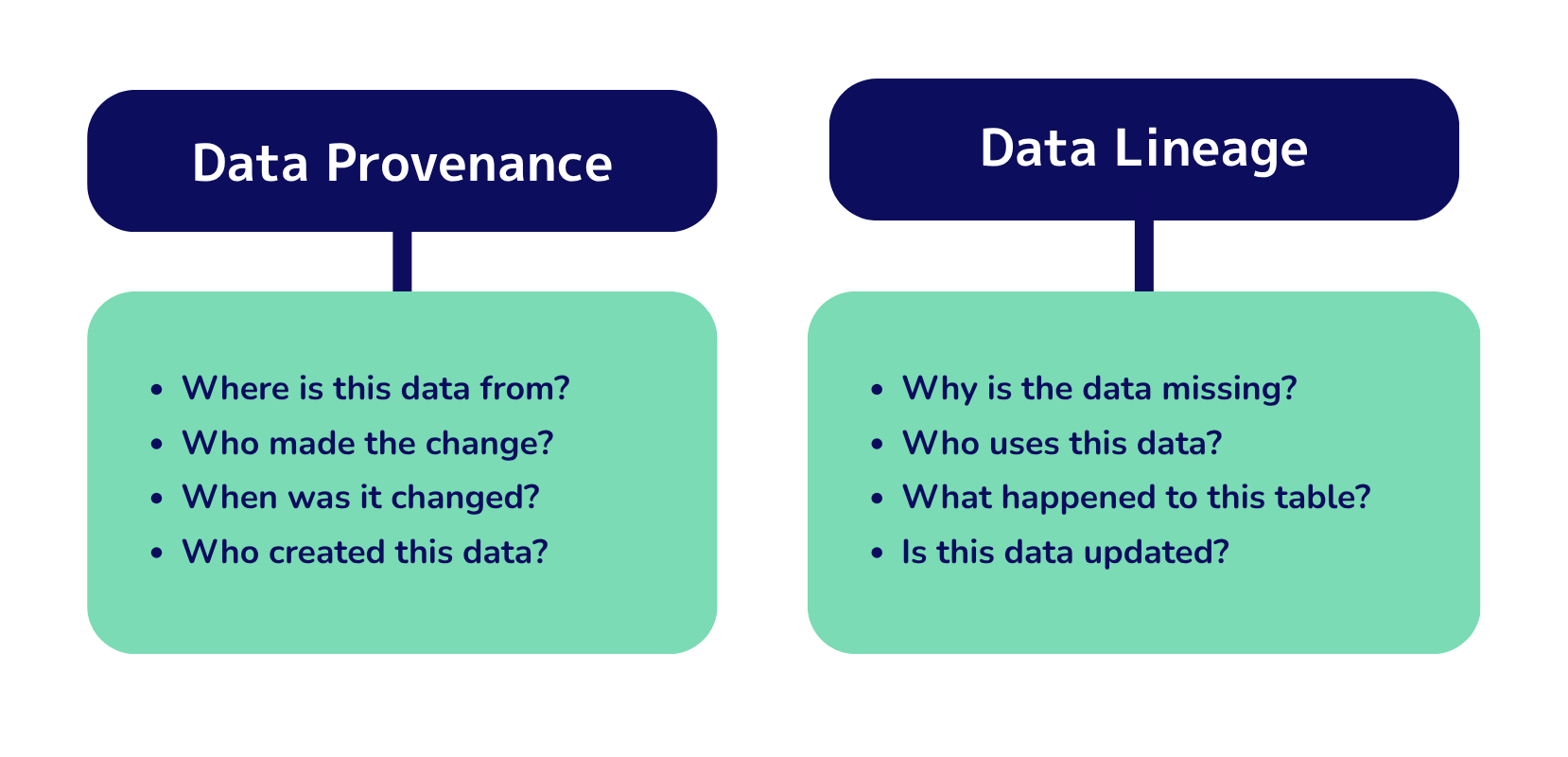
Data lineage tracks the complete experience of data from its origins to where it is now. The tracking documents how data moves and changes in systems and processes of all sizes. Organizations can use this visual map to understand data flows, dependencies, and transformations throughout their data pipeline.
Data lineage answers basic questions like “Where did this data originate?”, “What transformations has it undergone?”, “Where does it move next?”, and “Who uses it and for what purpose?”. Users can observe and trace different touchpoints along the data experience and prove it right for accuracy and consistency.
Data lineage includes several critical components:
- Origins: Shows where and when data was created or captured, and where it’s managed to keep (both internal and external sources)
- Characteristics: Describes what the data means in business terms (business metadata) and technical terms (technical metadata)
- Movements: Documents where data has been across hybrid ecosystems, from source to staging, to data warehouses and lakes, to analytics tools
- Transformations: Records how data was altered during its experience, including translations, quality rules, and reference data values
- Users: Identifies who or what accesses the data and for what reasons
Data lineage works as a vital troubleshooting tool beyond documentation. Teams can analyze root causes of data quality issues, track errors, and assess the effects of proposed changes. On top of that, it gives the transparency needed to meet regulatory compliance in industries of all types.
What is Data Provenance? (Definition and Use Cases)
Data provenance zeroes in on the historical record of data by capturing its derivation history from original sources. Lineage maps technical connections, but provenance highlights authenticity and integrity. It documents who created the data, when it was created, what changes were made, and by whom.
Data provenance answers questions like “Who created the data and when?”, “What changes have been made to the data and by whom?”, and “What is the original source of the data?”. This historical context builds credibility and traceability for data assets throughout their lifecycle.
Data provenance comes in two main classes:
- Backward provenance (retrospective): Tracks data history by identifying origin, transformations, and movement
- Forward provenance (prospective): Records how data will move and transform in future workflows
Data provenance helps many industries. Healthcare teams use provenance tracking to record patient data accurately from original collection through various changes. Financial institutions need provenance to audit transactions and trace them back to their origins. Scientific researchers rely on provenance to ensure their experiments can be validated and reproduced.
Data provenance serves as reliable infrastructure for AI systems, maybe even the most important part. AI systems become “black boxes” without reliable provenance mechanisms. The origins and transformations of training data stay hidden from users, regulators, and affected communities.
Data Lineage vs Data Provenance: A Comparative View
People often use these terms interchangeably, but data lineage and provenance serve different purposes in governance frameworks:
| Aspect | Data Lineage | Data Provenance |
| Primary Focus | Technical flow and transformations of data | Origin, authenticity, and historical context |
| Scope | Journey and transformations | History and authenticity |
| Key Questions | Where data flows and how it changes | Where data originated and who modified it |
| Typical Users | Data engineers, ML engineers | Legal, compliance, marketing, data leaders |
| Representation | Flow maps, system-to-system diagrams | Metadata logs, change logs, provenance chains |
| Governance Role | Ensures quality, prevents breakages | Ensures audit-readiness and regulatory trust |
These concepts work together in AI governance frameworks despite their differences. Teams can’t maintain data lineage without knowing data’s provenance. Understanding provenance works best when lineage is clear. Together they create a detailed framework to track, validate, and govern data across AI systems.
Both lineage and provenance play crucial roles in AI governance. Data and engineering teams use lineage to debug pipelines and understand dependencies. Legal and compliance teams rely on provenance to answer critical questions about data usage rights and audit requirements.
Core Components of an AI Data Governance Framework
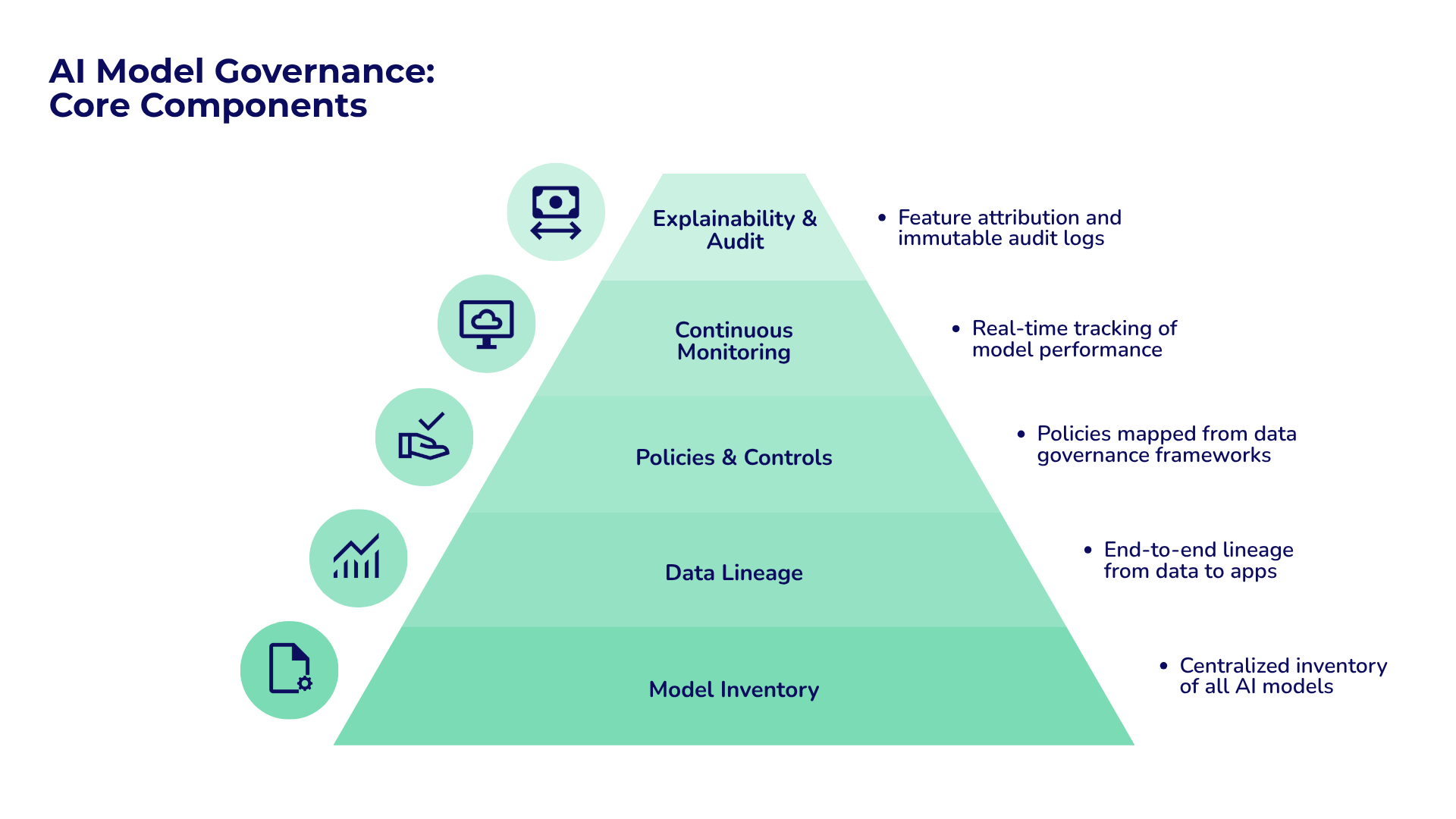
A strong AI data governance framework needs several interconnected components that work together to ensure data integrity and trustworthiness. The foundational concepts of lineage and provenance support governance systems that combine metadata, stewardship, and technical tracking capabilities.
Metadata Management and Data Catalog Integration
Metadata—the “data about data”—forms the foundation of effective AI governance. A well-structured metadata enables automation by providing keys to anchor processes, integration points, and algorithms. It also formalizes the context that data managers and consumers need to identify, communicate, and apply data properly. Organizations without proper metadata must rely on institutional knowledge to work with their data. This creates inefficiencies and governance gaps.
Effective metadata management involves:
- Technical metadata describing structure and format (schemas, table definitions, data types)
- Business metadata providing semantic meaning in plain language
- Operational metadata tracking runtime behavior and performance
- Usage metadata capturing how people interact with data
Organizations help users find, understand, and trust their data quickly by adding business context to technical metadata. AI-powered tools can now spot data types, usage patterns, and relationships automatically. This reduces manual input needs and makes catalogs more accurate.
Data Ownership and Stewardship Policies
Data stewardship covers the complete data lifecycle—from creation to storage, usage, modeling, archiving, and deletion. Clear ownership defines who controls specific datasets and who takes responsibility for their quality and proper use.
The NIST AI Risk Management Framework emphasizes accountability structures. These structures ensure that appropriate teams can map, measure, and manage AI risks effectively. Organizations need well-defined roles with specific responsibilities for data management, quality, compliance, security, and metadata management.
Data stewards connect with each layer of the governance model. They play essential roles in strategy implementation, regulatory compliance, and protection of sensitive information. They act as bridges between technical teams, business units, and external partners.
Lineage Tracking Across ETL and ELT Pipelines
Lineage tracking serves as the technical foundation of governance by documenting data movement and changes across systems. OpenLineage-compatible frameworks help users understand origins, transformations, and usage patterns. This improves trust, debugging capabilities, and governance controls.
Teams can capture lineage through several methods, including SQL query analysis, log-based tracking, and direct pipeline integration. Modern ETL tools and ELT platforms generate metadata during data movement operations. Catalogs can use this metadata to show simple source-to-destination mappings.
Column-level lineage proves valuable by identifying exactly which transformation caused an error. This turns a complex search into a guided process. In the end, organizations with proper implementation resolve issues faster, handle audit requests easily, and maintain trust in their analytics and AI systems.
Ensuring Data Quality Through Lineage and Provenance
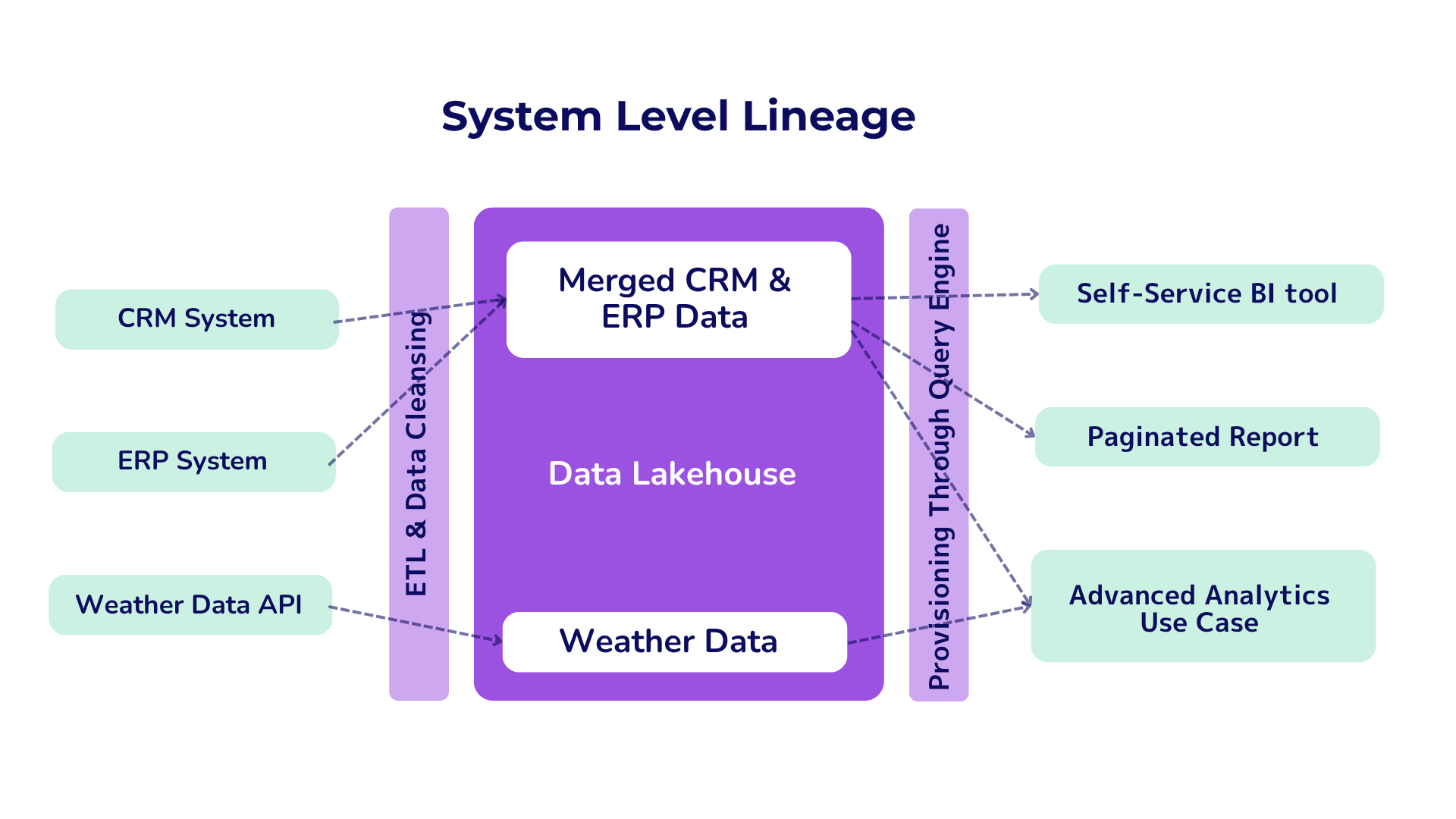
“You can have all of the fancy tools, but if [your] data quality is not good, you’re nowhere.” — Veda Bawo, Director of Data Governance, Raymond James Financial (at time of quote)
Reliable AI systems depend on quality data, and lineage and provenance are vital tools that maintain this quality. Organizations lose an average of $12.90 million annually due to poor data quality, as reported by Gartner. These losses demonstrate data quality’s financial risks.
Root Cause Analysis with Lineage Tools
Lineage tools help teams trace problems to their sources instead of spending time on manual investigations. Visual maps created through automated lineage scans of metadata across sources, ETL jobs, and destinations make troubleshooting easier. Backward lineage makes root cause analysis quicker by tracking data from its current state to its origin.
Monte Carlo’s tools help organizations fix over 1,000 reliability problems daily. Their solutions protect stakeholders from data pipeline failures and their associated costs. Similar tools like Ataccama let teams check data quality across tables. These tools automatically spot anomalies like unexpected values, missing records, or duplicates that transformation errors cause.
Data Quality Metrics and Validation Logs
Data governance works best by tracking these quality indicators:
- Data consistency: Ensuring uniform representation across systems
- Data completeness: Verifying no essential information is missing
- Data freshness: Confirming recency and timeliness
- Null counts: Tracking missing values that could affect analysis
- Schema changes: Monitoring modifications to data structure
Validation logs document quality checks throughout the data lifecycle. Modern AI-powered tools detect distribution changes by comparing current data profiles with historical baselines. These tools then convert the findings into readable alerts.
Impact Analysis for Schema and Source Changes
Database change errors cause serious production issues for 84% of stakeholders. This makes impact analysis before changes a vital step.
Organizations must understand how schema modifications affect their entire system. Tools that analyze metadata, lineage graphs, and SQL queries can spot potential problems before implementing changes. Changes to column data types or adding required columns without proper checks can lead to insert failures and data quality issues.
Data lineage helps teams understand dependencies and effects of proposed changes. This knowledge lets teams manage changes proactively rather than fixing failures after they occur.
Compliance, Audits, and Regulatory Readiness
Rules and regulations play a bigger role in how organizations handle AI data governance. Companies face huge financial losses and reputation damage if they fail to comply.
GDPR and CCPA Requirements for Data Traceability
GDPR and CCPA set strict rules about tracking data in AI systems. GDPR requires organizations to create data management plans. Companies must assess data protection risks and have Data Protection Officers in place. GDPR rules apply to AI systems that handle personal data, even though AI isn’t directly mentioned. Companies need to be open about how they use data and let people control their information. CCPA makes businesses keep detailed records of personal data usage. This pushes companies to build more transparent systems for managing data.
Audit Trails and Data Retention Policies
Good audit trails track every AI decision from start to finish. These include details about model versions, training data snapshots, and what features contributed to decisions. GenAI solutions need to log user IDs, prompts, responses, and filters. Companies should set clear timeframes for keeping AI training data and models. GDPR states that personal data should not be kept longer than needed. This means companies need storage policies that balance legal requirements with business needs.
Provenance Data for Risk Mitigation
Provenance data provides reliable support for managing risks. Companies struggle to prove their data sources are legitimate because there’s no standard way to verify them. License documentation was a big challenge at first, with mistakes happening more than half the time. In spite of that, tracking where data comes from helps spot wrong classifications quickly. This creates feedback loops that help AI models learn and make fewer mistakes over time.
Book a Readiness Call to get a full picture of your organization’s compliance status and create an AI governance plan that meets regulatory needs.
Tools and Best Practices for Implementing Lineage and Provenance
“Information is the oil of the 21st century, and analytics is the combustion engine.” — Peter Sondergaard, Former Executive Vice President and Global Head of Research at Gartner
Data lineage and provenance implementation needs the right tools and methods to track data flows in AI systems.
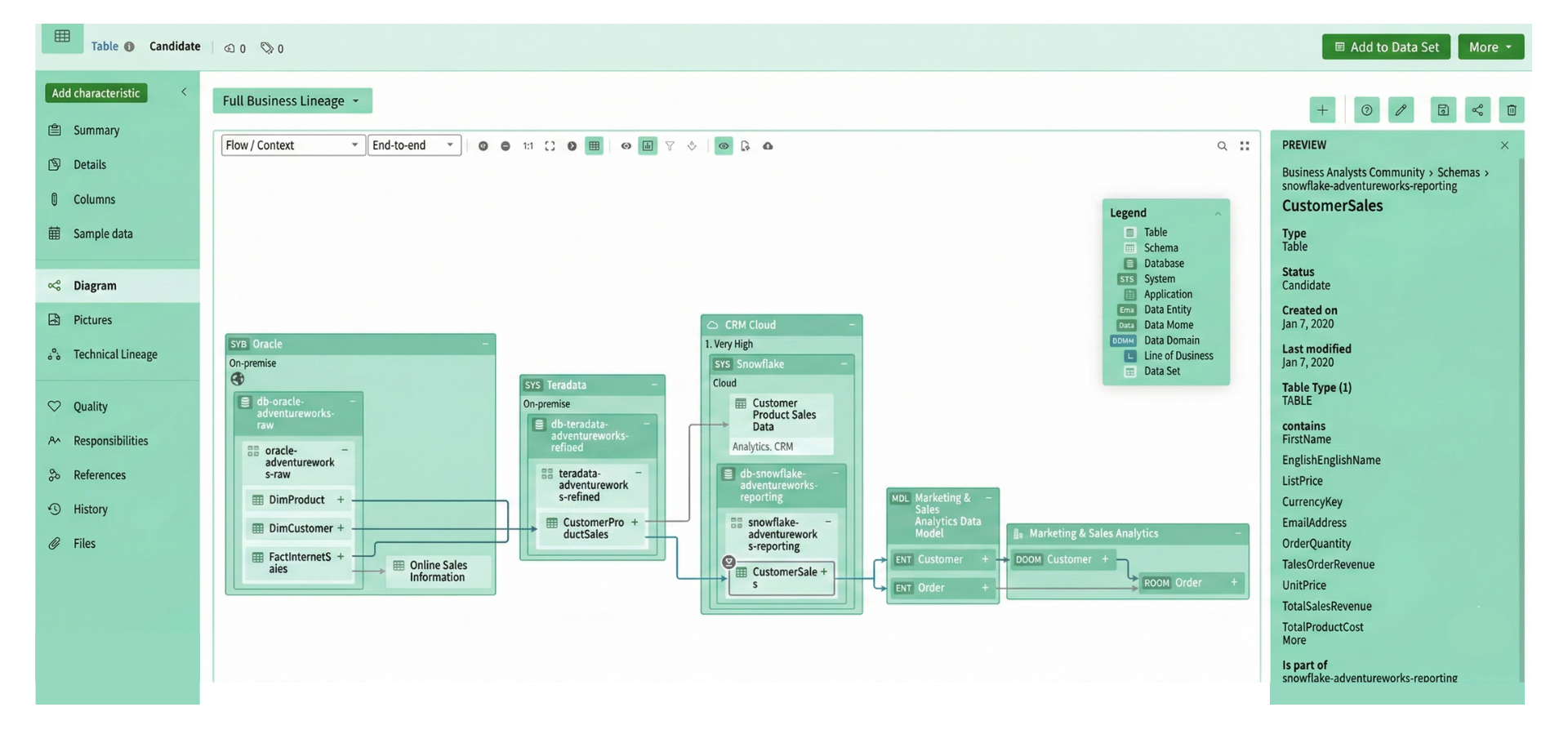
Popular Tools: Collibra, Atlan, OpenLineage
Collibra Data Lineage maps relationships between systems automatically and shows end-to-end visualization of data trips. The tool’s dual views provide both summary Business Lineage and detailed Technical Lineage, while supporting OpenLineage integration.
Atlan works as an AI-native metadata control plane that catalogs AI assets directly from AI/ML platforms. The platform traces data flows through the AI value chain with automated lineage tracking. Users can prove their AI’s reliability for audit and compliance needs.
OpenLineage has become the leading standard for lineage collection. This open-source framework uses a standardized metadata format for lineage events and stays technology-agnostic across data processing environments. The framework pairs with Marquez to provide visualization and metadata management features needed for lineage tracking.
Visualization Techniques: Linear, Graph, Temporal Views
Graph visualization offers a powerful way to show data lineage with clear representation of relationships between data elements. Experts point out that relationships in graph data models matter as much as individual data points.
Users can navigate through interactive lineage views like a canvas to zoom, filter, and focus on specific relationship paths. Many platforms enhance visual clarity by highlighting related artifacts while dimming others.
Bi-temporal views help teams see historical data trips and potential future effects. Teams can predict how changes might affect AI models before implementation.
Best Practices for Metadata Collection and Maintenance
Automation should take priority through up-to-the-minute schema detection and metadata harvesting from pipelines. Systems evolve constantly, making manual documentation outdated quickly.
Progressive implementation works best – start with job-level lineage before moving to message-level detail. A simple lineage across your entire pipeline beats detailed lineage for just a few components.
Cross-platform metadata synchronization needs bidirectional flows between core systems. This prevents fragmentation and keeps consistency across your AI infrastructure.
Metadata should serve as infrastructure rather than documentation. Companies that actively manage metadata could cut delivery time for new data assets by up to 70% by 2027.
Conclusion
Trust, quality, and compliance are the three pillars that support effective AI data governance in organizations deploying artificial intelligence systems. This piece explores how data lineage and provenance complement each other while serving different purposes. Data lineage creates a technical roadmap that shows data flows and transformations. Provenance builds authenticity and historical context needed to meet regulatory requirements.
Organizations that build resilient governance frameworks definitely gain competitive edges beyond just compliance. Detailed lineage tracking helps debug faster, cuts downtime, and improves data quality in AI pipelines. It also builds stakeholder trust through responsible data handling practices.
AI systems are becoming deeply integrated into business processes. The need to track data from origin to output has changed from a useful feature to a critical capability. Platforms like Collibra, Atlan, and OpenLineage provide great ways to get these governance capabilities. Each platform brings unique benefits to visualization and metadata management.
Data quality problems cost organizations millions each year. Proper lineage and provenance tracking creates value while reducing risks. Many organizations aren’t ready for governance challenges that come with advanced AI systems. Book a Readiness Call to review your current governance maturity and create a tailored roadmap that improves your AI data management practices.
Successful AI governance needs a balance between breakthroughs and responsibility. Organizations that establish clear ownership, maintain quality metrics, and document data flows create the foundations for valuable AI systems. These systems meet strict regulatory requirements. The future belongs to organizations that see data governance as resilient infrastructure rather than a compliance checkbox. This infrastructure enables trustworthy, explainable, and responsible artificial intelligence.
Key Takeaways
Understanding AI data governance through lineage and provenance is essential for building trustworthy, compliant AI systems that deliver reliable business value.
• Data lineage tracks technical flows while provenance establishes authenticity – Lineage maps how data moves and transforms across systems, while provenance documents origins and historical changes for compliance.
• Poor data quality costs organizations $12.90 million annually – Implementing robust lineage tracking enables faster root cause analysis and prevents costly system failures before they impact operations.
• GDPR and CCPA require comprehensive data traceability for AI systems – Organizations must maintain detailed audit trails and retention policies to satisfy regulatory requirements and avoid significant penalties.
• Automated metadata management reduces delivery time by up to 70% – Tools like Collibra, Atlan, and OpenLineage enable real-time tracking and visualization, transforming governance from manual documentation into strategic infrastructure.
• Progressive implementation beats perfect planning – Start with basic job-level lineage across your entire pipeline rather than detailed tracking for only a few components to achieve faster, more comprehensive coverage.
When organizations treat data governance as strategic infrastructure rather than a compliance checkbox, they create the foundation for AI systems that earn stakeholder trust while meeting increasingly stringent regulatory demands.
FAQs
Q1. What is the difference between data lineage and data provenance in AI governance? Data lineage tracks how data flows and transforms across systems, while data provenance focuses on the origin and historical changes of data. Both are crucial for AI governance, with lineage helping debug pipelines and provenance ensuring regulatory compliance.
Q2. How does data lineage contribute to improving AI data quality? Data lineage enables faster root cause analysis of data issues by visually mapping data flows. It allows teams to trace problems to their origins, detect anomalies, and implement quality checks throughout the data lifecycle, ultimately improving the reliability of AI systems.
Q3. What are some key components of an effective AI data governance framework? An effective AI data governance framework includes metadata management, data catalog integration, clear ownership and stewardship policies, and lineage tracking across ETL and ELT pipelines. These components work together to ensure data integrity and trustworthiness.
Q4. How do regulatory requirements like GDPR and CCPA impact AI data governance? GDPR and CCPA mandate comprehensive data traceability in AI systems. Organizations must maintain detailed audit trails, implement data retention policies, and ensure transparency about data use. This pushes companies to create more robust data management systems to comply with these regulations.
Q5. What are some best practices for implementing data lineage and provenance? Best practices include prioritizing automation for metadata collection, starting with job-level lineage before advancing to more granular tracking, establishing cross-platform metadata synchronization, and treating metadata as infrastructure rather than documentation. Using tools like Collibra, Atlan, or OpenLineage can also help in effective implementation.