
Poor data quality costs organizations $12.90 million each year. This makes AI data governance essential for business success. Humans and machines produce about 402 million terabytes of data daily in 2024. Such massive volumes create significant challenges for data management and integrity. The rise of generative AI and large language models in daily operations has shifted the focus. The question now focuses on how AI governance affects financial and operational results.
Data provenance tracks a record’s history from its origin through various changes. It has become essential to work effectively with governance. Companies that excel at data governance and AI frameworks show better results than their competitors. This happens especially when they maintain strong data culture and stewardship. Healthcare teams provide a perfect example. They use provenance tracking to maintain accurate patient records from collection through modifications. Clear governance rules, permissions, and audit trails have become essential. These ensure AI systems interact with approved data and deliver responsible outcomes.
This piece will show you how to create a detailed data provenance strategy. You’ll learn to strengthen your AI data governance framework by setting up ownership roles and building strong infrastructure that meets regulations.
Positioning Data Provenance in the AI Governance Lifecycle
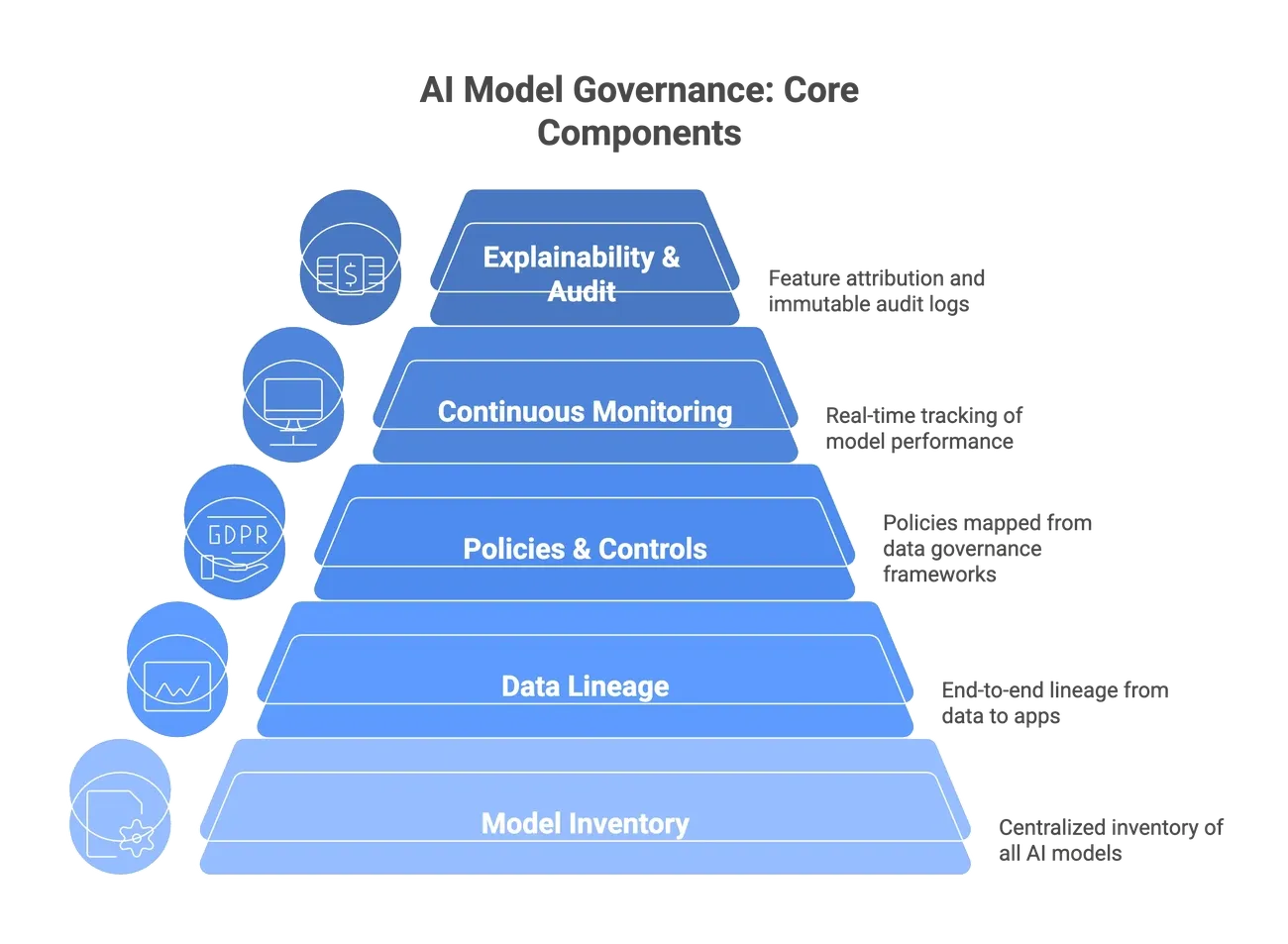
Image Source: Atlan
Data provenance is the life-blood of good AI governance. It creates a historical record that helps organizations track information’s trip from creation through changes. It goes beyond simple data cataloging by recording the complete lifecycle—who created the data, when it was created, what changes happened, and who made those changes. This detailed documentation helps reshape the scene by turning AI systems from mysterious “black boxes” into transparent, accountable technologies.
How provenance supports ai governance goals
Data provenance tackles several vital AI governance objectives. It builds authenticity and integrity through verifiable records of data origins. This verification has become more important now that studies show people can spot AI-generated content only 50% of the time—no better than guessing.
So, provenance documentation are the foundations of:
- Regulatory compliance: Organizations need to show they follow laws about data use, bias reduction, and system safety
- Risk management: Provenance data helps identify and fix potential issues
- Debugging capabilities: Teams can trace problems back to their source when issues come up
- Bias identification: Looking at data sources helps spot potential biases before they show up in AI outputs
Provenance also helps solve transparency problems in AI by answering vital questions: Where did the training data come from? Does it have intellectual property protection? Did it come from unreliable or biased sources? AI systems stay fundamentally unclear to users, regulators, and affected communities without these answers.
Data provenance is different from data lineage even though they’re related. Lineage tracks technical data flows at file and process levels, while provenance focuses on authenticity, integrity, and historical context of individual data elements. These concepts work together in governance frameworks. Lineage shows the technical path while provenance builds credibility. Data engineers use lineage to debug pipelines, while legal and compliance teams need provenance to check audit requirements and usage rights.
Connecting provenance to model versioning and monitoring
Models without provenance face big challenges. Data scientists often talk about building models with old data copies. They spend hours looking for file sources or wondering if they used the right processing scripts on the original data. These problems get worse when multiple teams work with data. Teams become afraid to make changes that might break dependencies.
Provenance becomes strong infrastructure to version and monitor models by:
- Enabling reproducibility: Teams can recreate exact training conditions and datasets with detailed provenance tracking
- Facilitating debugging: Provenance helps find specific data inputs or changes when models act strangely
- Supporting continuous monitoring: Regular provenance tracking spots data drift, poisoning attacks, or contamination
- Enhancing collaboration: Clear documentation lets multiple teams work with shared data confidently
Developers can track provenance in several ways, from manual documentation to automated systems. Some platforms track provenance automatically for all code run, which works well in cloud-hosted integrated machine-learning environments. The goal stays the same whatever method you use: keep an unbroken chain of documentation from data creation through model development and deployment.
We have a long way to go, but we can build on this progress in implementing detailed provenance. Organizations should create governance frameworks with clear rules for data management and tracking. Blockchain and data lineage tools can automate tracking and improve metadata records. Data provenance isn’t just about following rules – it’s vital infrastructure to build AI systems people can trust.
Establishing Ownership and Roles for Provenance Management
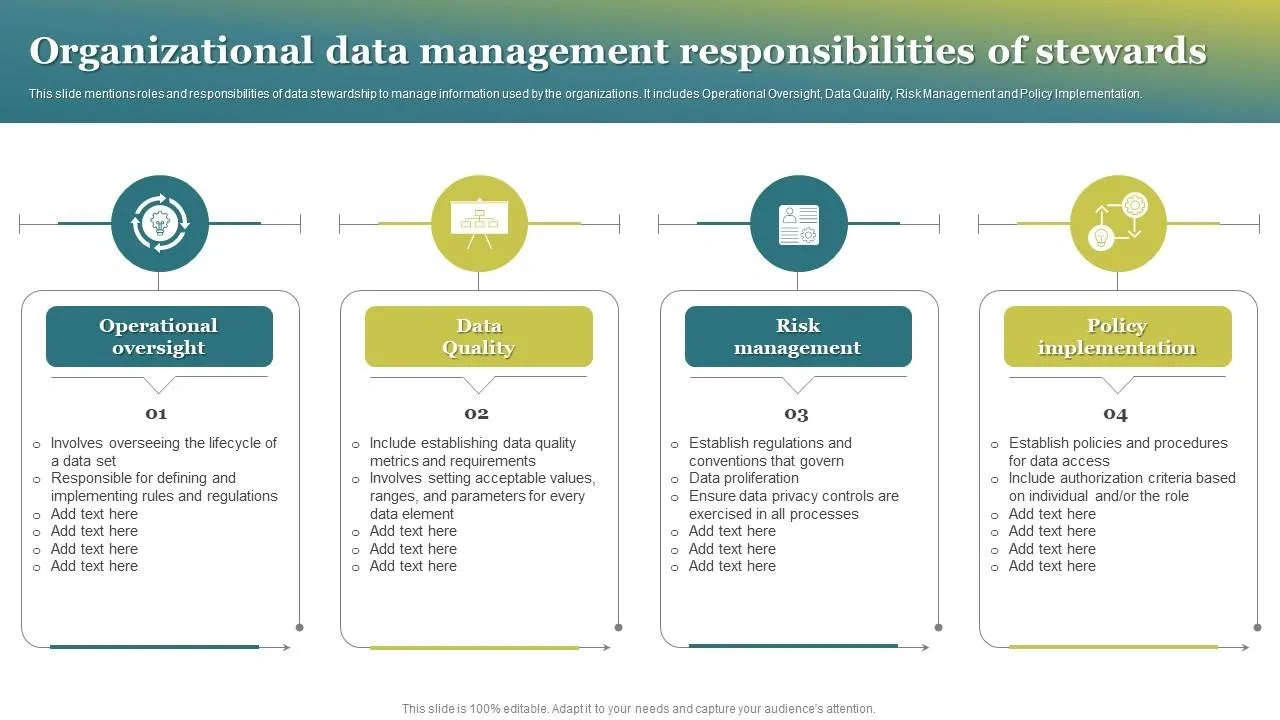
Image Source: SlideTeam
Organizations need clear ownership and defined roles in their data governance structure to manage provenance. Teams can map, measure, and manage AI risks throughout the data lifecycle with proper accountability systems in place. The NIST AI Risk Management Framework states these accountability structures are the foundations of responsible AI deployment.
data stewards vs ai stewards: responsibilities
Data stewardship is the foundation of provenance management that includes the complete data lifecycle from creation to deletion. Data stewards focus on five main responsibilities:
- Ensuring data integrity – Quality and accuracy maintenance supports effective decision-making
- Enforcing data privacy and security – Working with IT teams to implement strong access controls, encryption, and security measures
- Managing metadata – Documentation provides clarity about data origins
- Facilitating communication – They bridge technical teams and business executives to translate complex concepts
- Implementing governance policies – They arrange with both regulatory requirements and business objectives
Data stewardship isn’t usually a dedicated role. Business Analysts, Data Engineers, IT Managers, Department Heads, and Compliance Officers often handle these responsibilities.
AI stewards have emerged as an extension of traditional data stewardship roles. Their focus has shifted from human-generated data to overseeing how artificial intelligence processes information. They make sure it fits with existing governance standards. This creates a key difference: data stewards handle traditional data assets, while AI stewards tackle the unique challenges of AI systems and their data interactions.
These roles become crucial if you have provenance tracking. Data stewards link with each layer of the governance model. They implement strategy, ensure compliance, and protect sensitive information. They connect technical teams, business units, and external partners. AI stewards must also verify that AI systems document their data usage, transformations, and decision processes.
role of CDAO and compliance teams in provenance strategy
The Chief Data and Analytics Officer (CDAO) role has changed to address provenance challenges. Companies now see data as a strategic asset that needs dedicated leadership. The CDAO has become vital to data governance success. The role has grown from data management to analysis and AI.
CDAOs bridge technology initiatives and organizational strategy. They:
- Create complete policies and standards for quality, security, and regulatory compliance
- Build proper data governance practices into organizational culture
- Watch over provenance tracking systems that document data authenticity
- Find potential opportunities in the organization’s digital world
In spite of that, CDAOs can’t deliver economic value unless they cooperate with business line leaders and compliance teams. The biggest problem is finding the best way for business and analytics functions to work together.
Compliance teams strengthen provenance strategy by checking regulatory frameworks. AI helps monitor compliance with up-to-the-minute dashboards showing current risk posture, control effectiveness, and regulatory alignment. These teams and data stewards work together to implement strong access controls and encryption for sensitive information.
A practical approach to managing these connected responsibilities involves four main groups: Data Stewards who authorize data access, Trusted Designees who get authorization abilities from data stewards, Data Custodians who process and store data, and Data Users who access data for approved business processes.
Companies that arrange these roles strategically can extract practical insights, optimize operations, and create more business value from their data assets. This approach will give a solid foundation for responsible AI governance through data provenance.
Designing Controls and Policies for Provenance Enforcement
Image Source: Lifebit
Organizations need automated, enforceable mechanisms rather than traditional policy documents to implement proper data provenance controls. A recent Styra study shows 94% of technical decision-makers believe Policy-as-Code plays a crucial role in scalable security and compliance. About 88% of organizations already use it in their cloud-native applications.
policy-as-code for provenance enforcement
Policy-as-Code (PaC) revolutionizes provenance governance by turning theoretical frameworks into rules that systems can automatically enforce. Rather than depending on text documentation that needs human interpretation, PaC turns requirements into machine-readable instructions. These instructions verify and manage data integrity throughout its lifecycle.
Here’s a real-life example: A policy stating “personally identifiable information cannot be used for model training without explicit consent” becomes code that automatically:
- Scans datasets to identify PII
- Checks consent status
- Blocks unauthorized usage before violations happen
PaC brings several benefits to provenance enforcement:
- Consistency: Code-defined policies work uniformly across systems without human error
- Auditability: Version-controlled policies show who made changes and when
- Testability: Teams can test policies before deployment to avoid collateral damage
- Scalability: Automated enforcement handles thousands of resources without manual oversight
Organizations should weave provenance enforcement throughout the AI lifecycle – from development through deployment and monitoring. This layered approach will give you backup controls if one fails.
access control and retention policies for provenance data
Provenance data access controls must protect the original permissions tied to source information. AI systems, especially those using Retrieval Augmented Generation (RAG), pull data from many sources. Teams need to manage the original access restrictions.
Successful strategies include:
- Native access controls in AI data stores like vector databases
- Data segregation into separate instances based on access domains
- Application-layer enforcement that filters results based on user permissions
Organizations need retention policies that balance compliance needs with risk management. Clear patterns show these retention timeframes:
- Audit logs need at least twelve months of storage
- Prompts and responses usually need 90 days to one year
- Regulated industries often keep records for three to seven years, matching existing schedules
These periods cover normal data lifecycles. Legal holds stop any deletion during litigation or predicted investigations.
provenance-based risk scoring and prioritization
Provenance data varies in importance. More organizations now use risk-based scoring systems to focus on critical datasets and models. This helps teams:
- Apply tighter controls to sensitive data with high business impact
- Automate enforcement when risk scores pass certain thresholds
- Focus on fixing the most urgent issues
Risk scoring looks at data origins, transformation history, ownership chain, and usage patterns. Quantifiable risk values let organizations build what the US NTIA calls “defense in depth” – layered controls that match potential harm.
Advanced systems use AI-powered governance that classifies data, tracks lineage, enforces policies, and creates audit-ready evidence immediately. This changes governance from a tool-focused task into a coordinated system of accountability that adapts to changes in data, risks, and regulations.
Building a Scalable Provenance Infrastructure
Image Source: Actian Corporation
A reliable infrastructure serves as the technical backbone of any working AI data provenance strategy. Static metadata management systems can’t handle the volume, velocity, and complexity of data flowing through modern AI pipelines anymore. Organizations need smart, automated approaches to capture provenance in real time and enable governance at scale.
active metadata graphs for real-time provenance
Active metadata represents a fundamental change from static documentation to dynamic, connected knowledge. Traditional metadata just documents technical details. But active metadata captures signals from your data stack continuously and unifies them into a single, connected view. This approach creates an up-to-date foundation for AI governance by:
- Building relationship maps that automatically connect data assets to business processes
- Tracking behavioral patterns as users search, access, and analyze data
- Enriching metadata through automation rather than manual updates
- Converting observations into recommendations, alerts, and workflows
Active metadata acts as a catalyst for automation. These systems analyze connection strings, queries, and usage patterns to trigger appropriate actions. This creates a self-improving governance framework. The metadata graph makes this possible by linking technical details with business context and real-life behavior.
Collection systems gather technical metadata, usage signals, and lineage events from the ecosystem first. Then enrichment processes transform this raw data using machine learning and natural language processing techniques. A decision engine reviews quality, compliance, and access conditions to drive automated actions.
lineage-aware auto-actions and anomaly detection
Lineage-aware systems raise provenance from passive documentation to proactive governance. These systems track data’s trip continuously to detect patterns that might indicate problems or opportunities automatically. Oracle’s Data Catalog combines several string-matching algorithms with machine learning to calculate feature sets and provide recommendations based on data lineage.
This capability enables several powerful governance features:
- Automatic anomaly detection – Flagging unexpected null values, duplicates, or unusual patterns in data flows
- Predictive impact analysis – Forecasting how changes to source tables will affect dependent models
- Proactive risk management – Identifying potential risks before they cause problems
Lineage-aware systems can initiate automated responses beyond identifying anomalies. These systems can quarantine problematic data, raise tickets, or notify downstream stakeholders when issues arise. Incident triage and release management happen automatically based on predefined rules, which moves governance from reactive to proactive.
integration with data catalogs and model registries
Technical systems need to blend together for effective provenance infrastructure. Data catalogs organize technical and business metadata, while model registries track AI model versions and their associated artifacts.
Amazon’s research describes a simple system that extracts and manages metadata for common ML artifacts: datasets, models, predictions, evaluations, and training runs. The system speeds up workflows by tracking lineage and extracting metadata like hyperparameters, schemas, and neural network architectures automatically.
Model registries serve several vital governance functions:
- Storing model artifacts in a versioned manner for retrievability
- Tracking metadata about the model training process
- Managing the lifecycle of models from development through deployment
- Providing APIs for integration with other systems
Bi-temporal lineage capability becomes a critical feature during implementation. Organizations can roll back their entire data estate to any historical moment. This helps answer regulator questions about past decisions by showing the exact data sources, transformation logic, and quality rules that were in place at that time.
The Data Provenance Initiative shows this approach through the largest longitudinal study of datasets used to train LLMs. They created an open-source repository and interactive tool that traces data lineage. AI practitioners can filter and explore data provenance based on specific license conditions with their tool, which generates human-readable provenance cards for datasets.
A successful infrastructure implementation connects three essential elements: active metadata for real-time governance, lineage-aware systems for automated actions, and integrated catalogs and registries for complete artifact management. This technical foundation reshapes the scene of provenance from a documentation exercise into an active participant in your AI governance framework.
Aligning Provenance Strategy with Regulatory Frameworks
Organizations need detailed data governance strategies that arrange provenance capabilities with regulatory frameworks. This arrangement turns provenance from a technical capability into a compliance asset that helps manage risks and prepare for audits.
mapping provenance to NIST AI RMF and ISO 27701
The NIST AI Risk Management Framework offers a well-laid-out way to find, assess, and reduce risks in AI systems. The framework makes sure AI technologies support fairness, transparency, accountability, and privacy through four pillars: Govern, Map, Measure, and Manage. Data provenance supports the “Map” function by tracking data origins and transformations. This helps organizations spot potential risks in training data or processing methods.
ISO/IEC 27701:2025 has brought major changes to privacy management. The standard, which became independently certifiable instead of being just an ISO/IEC 27001 extension, now has expanded rules for AI-driven processing. These rules address algorithmic transparency, bias reduction, and accountability in automated decisions. Organizations can meet these requirements by tracking their data sources, transformations, and decision processes.
provenance support for DPIA and ROPA documentation
Data Protection Impact Assessments (DPIAs) are the foundations of incident response planning. They exploit findings to create better breach preparedness strategies. Detailed provenance data makes DPIAs stronger by providing solid evidence about data origins, processing purposes, and transformation methods. This approach, combined with security frameworks like NIST and ISO 27001, helps spot weaknesses in data flows before incidents happen.
Records of Processing Activities (ROPAs), required under Article 30 of GDPR, serve as the basic inventory for data governance. ROPAs must now document personal data processing, model logic, AI tool behavior, and jurisdictional exposure in the AI era. Automated provenance tracking can turn ROPAs from static documents into living metadata that grows with systems. This fundamental change from periodic documentation to continuous, automated discovery creates live audit readiness. The documentation stays current as AI applications evolve.
Measuring Success and Business Impact of Provenance
Image Source: Monte Carlo Data
Success metrics for data provenance implementation should connect technical capabilities to real business results. Companies now just need to adopt formal metrics that show responsible AI behavior and meet regulatory requirements.
kpis for provenance coverage and audit readiness
Specific indicators reveal governance maturity and form the foundation of effective provenance measurement. Research shows that only 30% of companies using AI track their governance performance through formal indicators. Companies with the best returns concentrate on:
- Inventory completeness – Percentage of AI systems documented with risk classifications
- Lineage coverage – Proportion of data assets with end-to-end provenance tracking
- Audit response time – How quickly teams can answer standard questions about AI decisions
- Incident detection rate – Speed at which potential bias or drift issues are identified
Teams measure audit readiness by checking how well systems maintain current documentation and version control. This makes provenance evolve from a background technical project into a visible driver of growth.
effect on data quality, model trust, and compliance posture
Data provenance creates measurable business value in many areas. Companies with complete data-provenance adoption see 73% higher marketing ROI and 88% experience less than one major compliance incident per year.
These results directly enhance three crucial business areas. Data quality improves as provenance monitoring traces the source of discrepancies. Stakeholder trust grows through documented AI system development with verifiable ethical practices. The compliance position strengthens with clear audit trails that detect tampering and ensure system integrity.
Companies that can trace, audit, and explain their AI systems deploy faster, certify more easily, and respond better to adversarial threats. This capability becomes a competitive edge rather than a cost center as regulations like the EU AI Act make provenance essential.
Conclusion
Data provenance stands as a cornerstone of responsible AI deployment. It has changed governance from a mere compliance checkbox into a strategic business edge. This piece explores how organizations can build detailed provenance tracking systems that document data origins, transformations, and usage patterns throughout the AI lifecycle.
Your provenance strategy needs clear ownership structures. Data stewards, AI stewards, and CDAOs must work together to establish accountability across the organization. These teams should implement Policy-as-Code approaches that automatically enforce governance requirements. Manual processes simply don’t scale anymore.
Strong technical infrastructure plays a vital role in successful provenance implementation. Active metadata graphs, lineage-aware systems, and integrated catalogs are the foundations of immediate governance capabilities that adapt quickly. Organizations can now automate anomaly detection and tackle risks before they become business problems.
Companies with strong provenance tracking see major benefits. Their data quality improves, model trust grows, and compliance posture strengthens significantly. Teams can deploy AI systems faster with fewer regulatory hurdles while stakeholder confidence remains high. This edge becomes crucial as frameworks like NIST AI RMF and ISO 27701 set stricter documentation requirements for AI systems.
All the same, many organizations find it hard to implement detailed provenance tracking because of technical complexity and shifting regulations. Those who need guidance should Book a Readiness Call with experts to assess their current capabilities and develop custom implementation plans.
AI governance’s future depends on more than system capabilities. We must verify how these systems reach their conclusions. Data provenance offers this vital transparency. It turns AI from mysterious black boxes into explainable, trustworthy tools that create business value while staying accountable.
Key Takeaways
Organizations implementing comprehensive data provenance strategies can transform AI governance from compliance burden into competitive advantage, achieving measurable improvements in data quality, regulatory readiness, and stakeholder trust.
• Establish clear ownership roles: Assign data stewards for traditional assets and AI stewards for AI-specific challenges, with CDAO oversight to bridge technical and business objectives.
• Implement Policy-as-Code enforcement: Replace manual documentation with automated, machine-readable rules that consistently enforce provenance requirements across all AI systems.
• Build active metadata infrastructure: Deploy real-time tracking systems with lineage-aware anomaly detection to proactively identify risks before they impact business operations.
• Align with regulatory frameworks: Map provenance capabilities to NIST AI RMF and ISO 27701 requirements to streamline DPIA and ROPA documentation processes.
• Measure business impact through KPIs: Track provenance coverage, audit response times, and incident detection rates to demonstrate ROI and governance maturity.
Organizations with full data provenance adoption report 73% marketing ROI improvements and 88% fewer compliance incidents annually, proving that comprehensive tracking systems deliver tangible business value beyond regulatory requirements.
FAQs
Q1. What is data provenance in AI governance? Data provenance is the historical record of data’s origin, transformations, and journey through AI systems. It provides crucial context for validating data authenticity, auditing processes, and ensuring transparency in AI decision-making.
Q2. How does data provenance differ from data lineage? While data lineage tracks technical data flows at the file and process level, data provenance focuses on authenticity, integrity, and historical context of individual data elements. Provenance establishes credibility, while lineage provides the technical pathway.
Q3. What role do AI stewards play in provenance management? AI stewards focus specifically on the unique challenges presented by AI systems and their data interactions. They ensure AI systems properly document data usage, transformations, and decision processes, extending traditional data stewardship to address AI-specific governance needs.
Q4. How can organizations implement Policy-as-Code for provenance enforcement? Policy-as-Code transforms provenance governance into executable rules that systems automatically enforce. This approach ensures consistency, auditability, and scalability by embedding provenance checks throughout the AI lifecycle, from development to deployment and monitoring.
Q5. What are some key metrics for measuring provenance success? Organizations can track provenance success through metrics such as inventory completeness (percentage of AI systems documented), lineage coverage (proportion of data assets with end-to-end tracking), audit response time, and incident detection rate. These indicators help demonstrate governance maturity and ROI.